
Optimizing Hardware Utilization: A Guide to Arcfra CPU Control
As computing power advances, enterprises face a dilemma in virtualization management. Traditional conservative allocation, meant to protect stability, results in chronically low CPU utilization. Furthermore, the explosion of core counts in modern Chiplet architectures often leads to massive resource waste without high-precision management.
Simultaneously, complex hardware evolutions have increased cross-node latency, threatening the performance of mission-critical apps and bottlenecking overall system throughput. These inefficiencies are increasingly costly as global hardware prices continue to climb, making idle capacity a major financial burden.
How can businesses maximize ROI and infrastructure efficiency without risking service stability?
Arcfra Enterprise Cloud Platform (AECP) addresses this by offering fine-grained CPU resource management. By integrating CPU partitioning, NUMA affinity, and QoS controls, AECP eliminates the “performance-cost” trade-off. This enables enterprises to significantly boost hardware utilization and slash procurement costs, delivering a vital competitive edge in a high-cost hardware market.
Three Challenges of Traditional Computing Resource Management Approaches
In large-scale VM deployments, traditional CPU management strategies face a fundamental conflict between stability, cost, and performance. This is primarily reflected in three dimensions: the struggle to balance reliability with resource costs, hardware-driven resource waste, and performance degradation from cross-NUMA access — all of which have become core obstacles to enterprise IT efficiency.
Escalating Conflicts Between Low Utilization and High Costs
Under traditional CPU resource management, enterprises often adopt a “low-watermark” strategy to cap average CPU utilization — often below 60% — to ensure the stability of core systems like databases. The more critical the systems are, the lower the threshold can be. Some IT teams may also reserve extra buffers for peak loads.
While this “stability over efficiency” approach mitigates resource contention, it keeps average server utilization low while driving up procurement and O&M costs. Such inefficiency fails to meet the demands of modern enterprise for IT centralization and cost-effectiveness.
Hardware Evolution Exacerbating Resource Waste
The maturation of Chiplet technology has triggered an explosion in CPU core counts, with recent hardware evolving to deliver 3 to 4 times the cores available just five years ago. (Source: This Chart is Key to Understanding the Growth of AI, STH)
While higher core counts should theoretically allow for greater VM density and efficiency, the lack of fine-grained resource management in production often forces enterprises to suppress CPU utilization thresholds to avoid performance risks. Consequently, the surge in cores has paradoxically expanded the scale of idle capacity, creating a vicious cycle where higher hardware investment leads to greater resource waste.
Performance Constraints of NUMA Architecture
The advancement of Chiplet technology has also significantly increased cross-node memory access latency within NUMA architectures. Without effective NUMA affinity strategies, accessing remote memory cells is far slower than local access. As core counts rise, this latency becomes a primary bottleneck, leading to increased response times and sharp performance drops for critical applications.
Worse still, the increasing density of VMs on a single physical server causes NUMA topology complexity to skyrocket, resulting in untraceable performance degradation — a major pain point for O&M teams. Additionally, larger-scale VM deployments intensify resource contention, which further exacerbates the negative impact of cross-node access latency. This creates a vicious cycle that significantly restricts overall system throughput and critical business performance.
In real-world virtualized environments, these issues are interconnected. The explosion of core counts driven by Chiplet technology amplifies both resource waste and NUMA latency, while the over-provisioning strategies used to mitigate performance risks further drag down resource utilization. This “performance-cost” trade-off forces enterprises into a dilemma: sacrificing high performance and stability for better utilization, or bearing exorbitant costs to maintain them.
To break this deadlock, a breakthrough in resource scheduling is essential: ensuring core business performance through physical-level isolation, while simultaneously enhancing utilization via fine-grained and elastic resource allocation — all while avoiding the performance pitfalls of NUMA architecture.
How Does Arcfra AECP Balance Stability, Cost, and Performance Through CPU Resource Partitioning?
To balance critical business performance with resource utilization, Arcfra AECP allocates CPU resources into three dynamic pools:
- System Reserved Pool: Dedicated to system services (computing, storage, networking, etc.) with support for dynamic adjustments, ensuring infrastructure stability remains unaffected from workload fluctuations.
- Exclusive VM Pool: Isolates resources for performance-critical workloads like databases and middleware. It utilizes NUMA affinity scheduling to minimize latency and meet extreme performance demands.
- Shared VM Pool: Hosts general business applications using QoS policies for flexible resource management. This allows high-priority tasks to preempt resources, maximizing utilization while maintaining baseline performance.
By combining physical isolation with elastic scheduling, this approach ensures “zero-interference” for core operations while enabling dynamic reuse of idle capacity, effectively resolving the long-standing conflict between stability and cost-efficiency.
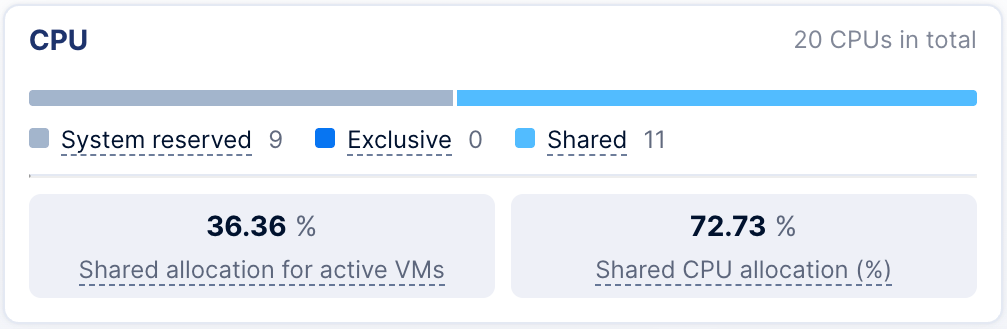
System Reserved Pool: Ensuring Infrastructure Stability
As the core of the underlying infrastructure, the System Reserved Pool is dedicated to serving critical system services, including the virtualization control plane, distributed storage services, networking, and O&M monitoring components.
By implementing independent resource reservation and physical isolation, it ensures that system services remain responsive even under heavy business loads, preventing management plane latency or service interruptions caused by resource contention.
Furthermore, system resource allocation is dynamically adjusted based on performance and networking requirements. For instance, a cluster enabling Boost Mode will be reserved 3 additional CPU cores, while enabling RDMA or active-active clusters reserved 1 additional core. This approach guarantees infrastructure reliability while simultaneously minimizing resource waste.
Exclusive VM Pool: Resource Guarantees for High-Performance Workloads
In enterprise IT environments, mission-critical workloads such as databases and real-time trading systems demand rigorous computing performance and stability. In traditional virtualized architectures, performance fluctuations and latency issues caused by resource contention often pose a significant threat to business continuity.
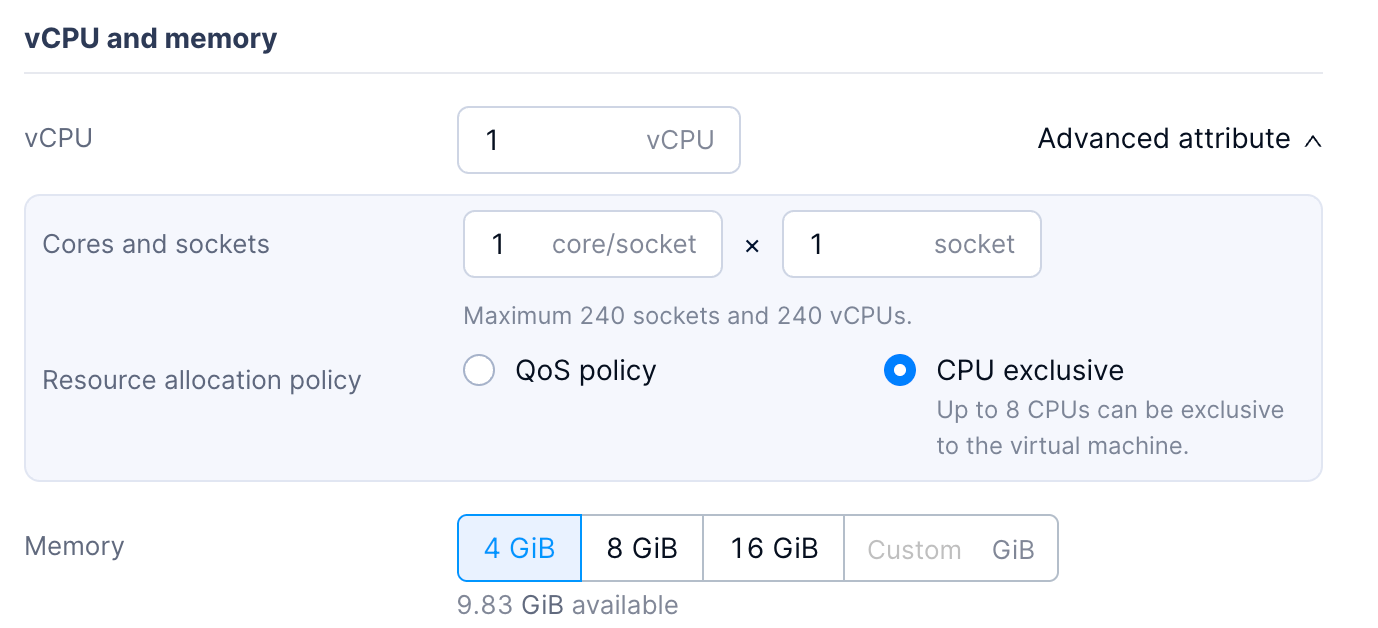
CPU Exclusivity
To meet the rigid resource requirements of high-performance workloads, Arcfra AECP provides CPU Exclusivity feature, utilizing physical-level isolation to ensure dedicated computing power for high-priority services. This feature binds virtual CPUs (vCPUs) to physical cores (pCPUs). Combined with a pCPU isolation mechanism, it ensures that exclusive resources are dedicated solely to the target workload, preventing preemption by other virtual machines.
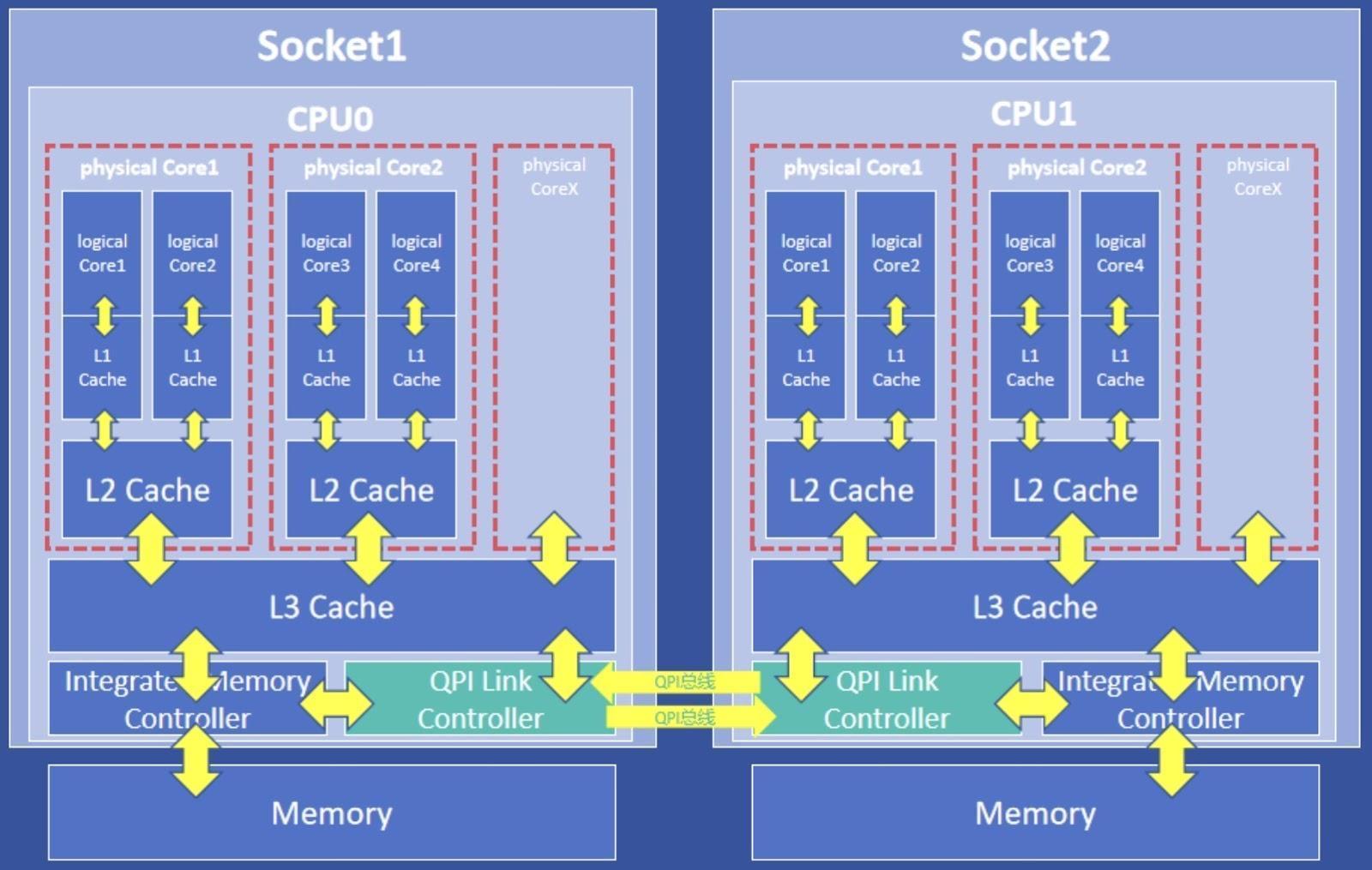
NUMA Affinity Scheduling
To meet the demands of mission-critical workloads for extreme performance, Arcfra Cloud Operating System (ACOS) 6.2 and later versions automatically apply NUMA affinity scheduling strategies to VMs with CPU Exclusivity enabled.
In a NUMA architecture, memory devices and CPU cores are assigned to different NUMA nodes. The memory access time depends on the relative position between the CPU and the memory; latency can be minimized by prioritizing access to local memory.
Consequently, for VMs with CPU Exclusivity enabled, the NUMA affinity scheduling strategy prioritizes allocating vCPUs within the same NUMA node. It also ensures that memory is allocated from the same node upon VM startup, reducing cross-node access latency and further enhancing overall VM performance.
Shared VM Pool: Flexible Management and Higher Utilization
For VMs hosting general workloads, shared computing resources are often used to maximize utilization. However, high CPU overcommitment ratios pose a significant risk of resource contention; without proper controls, critical services may fail to obtain sufficient resources, or a single VM’s excessive usage could impact all other workloads.
To address this, ACOS 6.2 and later verisons support CPU QoS settings, enabling enterprises to flexibly manage shared resources through the configuration of CPU shares, reservations, and limits.
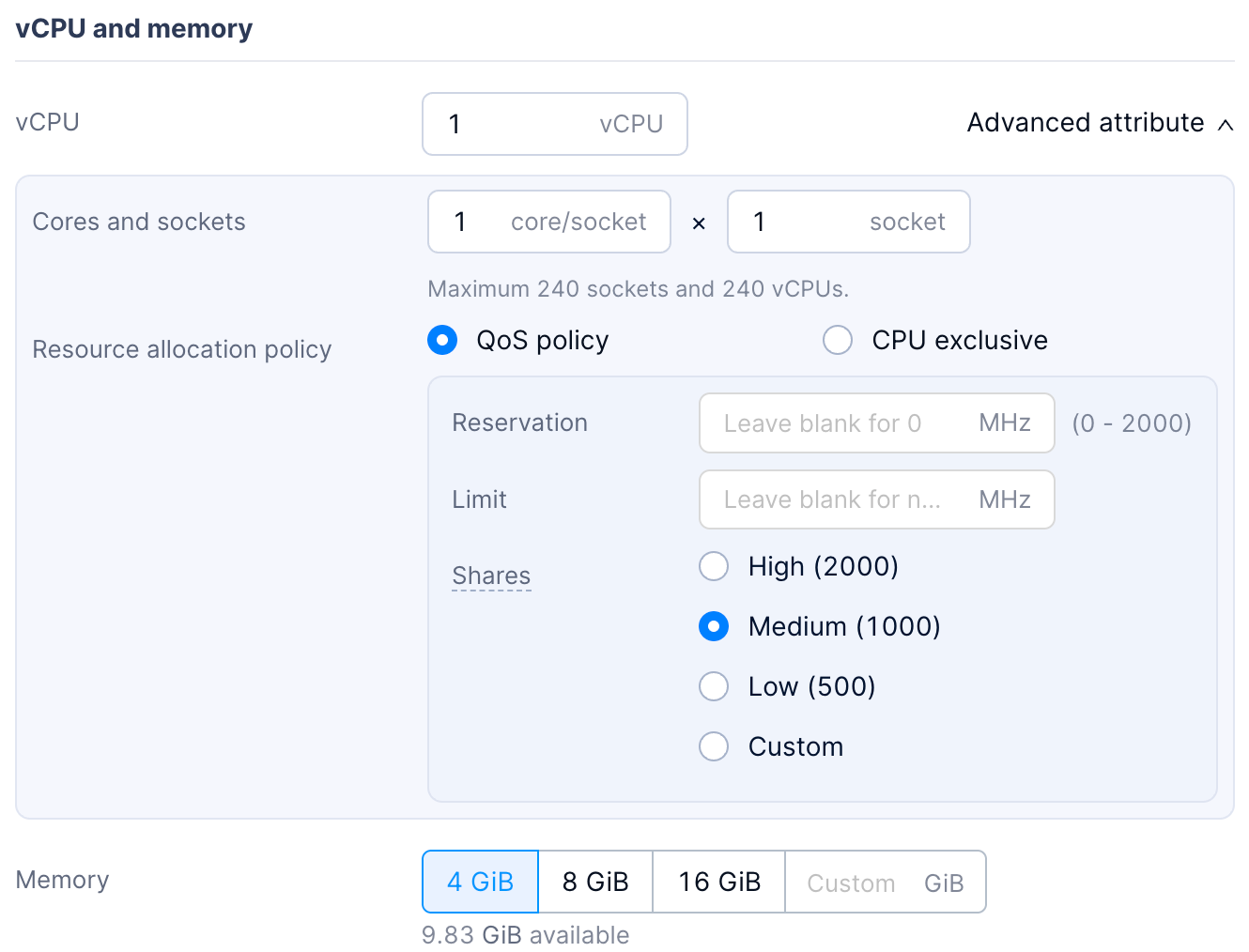
CPU Shares
When CPU resource contention occurs on a host, the varying importance of workloads across different VMs necessitates distinct allocation priorities. CPU Shares allow users to clearly define a VM’s priority during contention. This enables the system to automatically bias resource distribution toward VMs hosting more critical services, thereby assuring actual business running.
CPU Reservation
In practice, VMs hosting critical or long-term stable workloads require consistent and sufficient CPU resources to prevent latency or interruptions caused by resource contention. While CPU Shares define priority, the actual allocated capacity can still diminish as the number of VMs increases or total resources become limited, potentially failing to meet operational requirements.
On the other hand, the existing CPU Exclusivity feature, while robust, prevents idle resources from being reused and is limited by the total number of physical cores. This leads to lower host density and higher costs, making it suitable only for a small subset of extreme-performance workloads.
To address a broader range of stability-focused scenarios, users can configure CPU Reservation. By reserving resources at a finer granularity, CPU capacity is distributed more flexibly across more VMs. Crucially, when a VM is idle or not utilizing its full reservation, the surplus can be reassigned to other workloads, significantly improving overall CPU utilization.
CPU Limit
In cluster management, business teams often tend to request more resources than are actually required to ensure operational stability or prepare for contingencies. However, for O&M administrators, this increases the risk of severe resource contention.
To address this, CPU Limit allows administrators to set an upper bound on a VM’s resource consumption. This enables flexible reclamation and management of CPU resources without altering the VM’s requested configuration. Simultaneously, it prevents sudden workload spikes or anomalies from monopolizing CPU cycles and impacting the performance of other VMs.
Use Cases: Improving Computing Hardware Utilization
A financial institution needs to concurrently run a core trading system (high priority) and a batch report generation service (low priority) on its virtualization platform. Originally, the O&M team relied on a traditional resource management approach of “static overcommitment + manual observation” to ensure business stability:
- Resource Allocation: VMs were deployed based on total available vCPUs with fixed overcommitment ratios (e.g., 2:1 for production, 5:1 for testing). A 64-core host with Hyper-Threading enabled would support a maximum of 256 vCPUs of production VMs.
- Observation & Adjustment: After initial deployment, VM counts were adjusted based on CPU utilization monitoring. If total utilization exceeded 60% during peak hours, low-priority workloads were manually migrated.
This model presented two major challenges:
- Resource Waste: To avoid performance fluctuations in the trading system, actual average utilization often remained below 50%, leading to high hardware costs.
- Performance Risks: During traffic spikes, low-priority tasks (like report generation) compete for resources with the trading system, causing transaction latency to surge and potentially triggering risk control alerts.
By leveraging Arcfra AECP’s CPU Resource Partitioning capabilities, the enterprise effectively optimizes physical resource utilization:
- System Reserved: 8 vCPUs are reserved to ensure the stability of system services.
- Exclusive for Critical Business: 32 vCPUs are dedicated to the core trading system. These exclusive VMs are immune to resource contention, allowing their average CPU utilization to increase to 80%.
- Shared for Other Workloads: The remaining 88 vCPUs support an increased overcommitment ratio of 3:1 (deploying 264 vCPUs). Through priority and reservation policies, the CPU utilization threshold is raised to 75%, with idle nighttime resources reclaimed for batch processing.
Under this scheme, average cluster CPU utilization increases from 50% to approximately 75%, significantly reducing hardware waste. Additionally, the total vCPU capacity on the same hardware grows from 256 to 296. This solution not only guarantees the stability of core production services but also substantially improves physical resource efficiency, delivering true “cost reduction and efficiency enhancement.”
Conclusion
To resolve the conflict between resource waste and performance assurance, Arcfra AECP manages CPU resources through a three-tier dynamic pool system: System, Exclusive, and Shared. The System Reserved Pool independently ensures the stable operation of infrastructure services. The Exclusive VM Pool provides zero-interference, peak performance for mission-critical workloads via physical-level isolation and NUMA affinity scheduling. The Shared VM Pool utilizes QoS policies to elastically allocate resources between high and low-priority tasks, maximizing utilization. Together, these tiers achieve the operational goal of “rock-solid stability for core business while making full use of idle resources.”
Furthermore, users can integratedly use DRS strategy to achieve load balancing of computing resources across multiple hosts.
Arcfra simplifies enterprise cloud infrastructure with a full-stack, software-defined platform built for the AI era. We deliver computing, storage, networking, security, Kubernetes, and more — all in one streamlined solution. Supporting VMs, containers, and AI workloads, Arcfra offers future-proof infrastructure trusted by enterprises across e-commerce, finance, and manufacturing. Arcfra is recognized by Gartner as a Representative Vendor in full-stack hyperconverged infrastructure. Learn more at www.arcfra.com.