
Arcfra AECP 6.3 Deep Dive | Full-Stack Disaster Recovery with Synchronous Replication and Arcfra Operation Center High Availability
In traditional disaster recovery (DR) solutions for enterprise critical business systems, the focus is often placed on the data layer, emphasizing data backup and replication capabilities. This approach, however, frequently overlooks the protection of the business layer and the control layer. As a result, in real disaster scenarios, although “data can be restored,” the complexity and unpredictability of business recovery make it difficult for overall disaster recovery capabilities to meet the continuity requirements of critical business systems.
With Arcfra Enterprise Cloud Platform (AECP) 6.3, VM-level native synchronous replication (RPO=0) and the Arcfra Operation Center (AOC) control plane high-availability (HA) are introduced. This provides native disaster recovery capabilities comparable to high-end storage arrays, ensuring full-stack protection for the continuity of critical business systems.
- VM-level Native Synchronous Replication: Achieves real-time, VM-granular synchronous replication with guaranteed data consistency (RPO=0). It tolerates network fluctuations without requiring full cluster active-active deployment, making it ideal for critical business workloads that balance data security with cost control.
- AOC HA: Supports automatic failover across the cross-site control plane, ensuring continuous resource scheduling and effective execution of disaster recovery even under site-level failures.
By combining existing asynchronous replication and backup capabilities, AECP 6.3 offers an end-to-end disaster recovery solution that covers data protection, business recovery, and platform management, ensuring a full-stack disaster recovery loop.
Challenges of Mainstream Infrastructure-Level Disaster Recovery Solutions
For disaster recovery (DR) of critical business systems, enterprise solutions at the infrastructure layer typically follow two main approaches.
1. Traditional three-tier-architecture-based DR
These solutions usually rely on external storage arrays, replication software, and coordination among multiple components to achieve data protection and business recovery. In practice, they often face several challenges:
- High cost: Dependence on dedicated storage hardware and multiple overlapping systems results in significant construction and O&M investment.
- Complex architecture: Computing, storage, network, and disaster recovery capabilities are distributed across different systems, leading to heavy deployment and operational burdens.
- Fragmented capabilities: Data replication, business recovery, and management control reside in separate layers, making it difficult to form a unified DR system.
2. Stretched HCI clusters
While this solution simplifies architecture and provides more real-time data protection compared with traditional solutions, it still has limitations in practice:
- Cluster-level protection: It is difficult to implement differentiated DR for VMs based on business importance, and non-critical workloads still bear the same high protection cost as critical ones.
- Network requirements: Dependence on stable, low-latency L2 networks makes business continuity sensitive to network fluctuations.
- Limited verifiability: While focusing on high availability, flexibility in data protection policies, DR scheduling, and recovery drills remains constrained.
Given that enterprises increasingly demand an integrated DR system that uniformly offers data protection, business continuity, and control capabilities, the key evolution for enterprise cloud platforms is to provide a comprehensive DR framework that covers different failure scenarios, while maintaining architectural simplicity, real-time performance, flexibility, and verifiability.
AECP 6.3: Introducing Native Synchronous Replication & AOC HA for Full-Stack DR
AECP 6.3 is designed to deliver a native disaster recovery system within the hyperconverged architecture, providing DR capabilities comparable to high-end storage arrays. This release focuses on strengthening two core capabilities:
VM-Level Native Synchronous Replication (RPO=0)
In the traditional architecture, achieving RPO=0 synchronous replication usually relies on high-end storage arrays, which are complex to deploy and expensive. AECP 6.3 integrates this capability directly into the hyperconverged architecture, providing real-time, VM-level synchronous dual-site writes with strong consistency guarantees. This ensures zero data loss while significantly reducing DR system complexity:
- Synchronous data writes into the source and target sites. Under normal network conditions, replica data remains consistent at all times.
- Tolerate Network fluctuations. In case of network latency or short interruptions, replication automatically degrades without blocking source workloads, and resumes syncing to replicas once the network is restored, ensuring eventual consistency.
- No dependency on external storage arrays. Achieve RPO=0 on a standard hyperconverged architecture.
- Protect workloads at the VM level, enabling both flexibility and fine-grained management.
AOC Control Plane High Availability (HA)
Beyond data protection, enterprise disaster recovery also depends on reliable management and control. AECP 6.3 strengthens the HA capabilities of the control plane:
- Support cross-site deployment to prevent single points of failure from affecting overall controllability.
- Even in site-level failure scenarios, AOC continues to provide resource scheduling and DR orchestration.
- Guarantees that recovery operations can be executed during DR, not just that data is available for restoration.
By combining existing asynchronous replication and backup capabilities, AECP 6.3 establishes a full-stack disaster recovery loop covering both data and control planes. Enterprises gain not only reliable data recovery but also business continuity and unified management, achieving a true upgrade to full-stack DR capabilities.
Technical Insight: Achieving RPO=0 with VM-Level Synchronous Replication
Compared with building active-active stretched clusters, VM-level synchronous replication does not require cluster-level DR construction. It can automatically tolerate DR network fluctuations and reduce the consumption of network resources.
Implementation Mechanism
Data Synchronization
In AECP, data synchronization is achieved through two stages: replication tasks and synchronization tasks.
Replication Tasks
These tasks perform the initial data synchronization between the primary and secondary sites, establishing a consistent data baseline:
- Perform a full data copy of the source VM and create the corresponding replica VM at the target site.
- Establish a consistent starting point between primary and backup data, laying the foundation for subsequent synchronization.
Synchronization Tasks consist of two phases:
- Incremental Catch-Up Phase: During this stage, data discrepancies generated during the replication process are caught up. The latest data is synchronized to the replica to ensure that the primary and backup data achieve strict consistency, enabling a smooth transition to the real-time synchronization phase.
- Real-Time Dual-Write Phase: Once fully synchronized, all writes are applied simultaneously to both the source and target ends. A write operation is considered successful only after completion on both sides. Under normal network conditions, primary and backup data remain strongly consistent at all times, achieving RPO=0.

Failure Handling
- Failover: When the source site becomes unavailable, service can be switched to the replica VMs, allowing the replica to take over production workloads.
- Failback: Once the original site is restored, the replication service performs reverse replication, synchronizing the incremental data generated on the replica during failover back to the original VMs to reestablish consistency between primary and backup.
Note: Currently, failover and failback operations must be performed manually.
Key Features
Automatic Degradation to Prioritize Production
In scenarios such as network fluctuations or increased write pressure, the system can automatically trigger a replication degradation to prioritize the stability of production workloads. This prevents performance fluctuations or service interruptions caused by synchronous replication.
Flexible Recovery Point
Multiple methods are supported for generating recovery points. When data is in a ”synchronized“ state, recovery points can be generated periodically. If an anomaly occurs during synchronous replication, the system can automatically create recovery points to preserve critical data. With this feature, users can select from different time points during failback, enhancing both flexibility and control over recovery operations.
Multiple Approaches to Improve Recovery Efficiency
- Network Mapping: During failover, replica VMs can automatically adopt network and IP settings according to predefined policies. This adapts to disaster recovery deployment requirements in complex network environments, reduces manual intervention, and accelerates business takeover. In scenarios where primary and replica reside in the same VPC and subnet, network-level HA can be further achieved.
- Disaster Recovery Orchestration: Supports batch execution of failover operations and allows defining the startup sequence and delay of VMs. This ensures workloads recover in the correct order according to dependencies, avoiding service anomalies caused by improper startup order.
Efficient Disaster Recovery Drill Options
Multiple DR drill modes are provided to balance safety and effectiveness, meeting enterprise routine drill and compliance requirements:
- Non-intrusive simulation mode: During drills, replica VMs run in an isolated network. Users can access recovery point data and validate business availability, ensuring DR procedures are reliable and verifiable without impacting production.
- Realistic scenario mode: Scheduled failovers are conducted following the actual DR process, including full business takeover and switching operations. This validates the system’s recoverability and stability under real-world failure conditions.
Comparison of Disaster Recovery Solutions
Stretch Cluster Active-Active vs. Synchronous Replication
| Feature | Mainstream Stretched Cluster (Including AECP Active-Active) | AECP Synchronous Replication |
|---|---|---|
| Protection Granularity | Cluster-level (Critical and non-critical workloads must be deployed together) | VM-level (Protects critical workloads selectively) |
| Network Requirements | Requires stable, low-latency L2 network | Supports L3 networks; tolerates certain levels of latency |
| Network Fault Tolerance | ❌ Network anomalies may trigger global failover | ✅ Supports latency tolerance; manual failover per object |
| Fault Domain Isolation | ❌ Sites function as a single logical cluster; no isolation | ✅ Production and DR clusters are completely independent |
| Management Platform | Single control plane (Single AOC management) | Supports single or dual control planes (Single/Cross-AOC) |
| Erasure Coding (EC) | ❌ Supports 3-replica mode only | ✅ Supports custom EC/Replica policies |
| Failover Mechanism | Automatic | Manual |
| Recovery Time Objective (RTO) | Unplanned: Automatic failover (minutes) Planned: RTO = 0 | Unplanned: Manual failover (5+ minutes) Planned: Minutes |
| Oracle RAC Support | ✅ Supports shared volumes | ❌ Currently unsupported |
| Deployment Flexibility | Requires symmetrical resource deployment | Supports on-demand, flexible resource deployment |
| Use Cases | Core systems requiring maximum business continuity | Critical workloads balancing data security with cost efficiency |
Typical Use Cases
Stretched Cluster Active-Active: Ideal for core systems with extremely high business continuity requirements:
- No business interruption: Supports automatic failover with ultra-low RTO (minutes or even less)
- Applications with clustering capabilities: Such as Oracle RAC and other applications that rely on shared storage or multi-node coordination
- Mature infrastructure conditions: Stable, low-latency network connectivity between sites with sufficient resource investment.
Synchronous Replication: Ideal for critical workloads that balance data protection with cost control:
- Zero data loss with brief interruption tolerance: Provides RPO = 0 data protection with manual failover.
- More controllable resource investment: Protects only critical workloads without requiring a full active-active deployment.
- More flexible network requirements: Supports cross-L3 network connectivity and tolerates latency and fluctuations.
- Greater architectural flexibility: Allows independent planning of production and disaster recovery resources, enabling gradual evolution of disaster recovery capabilities.
Traditional 3-Tier Architecture DR vs. AECP Synchronous Replication
| Feature | Traditional Three-Tier Architecture DR | AECP Synchronous Replication |
|---|---|---|
| Synchronous Replication Capability | Achieved through a combination of storage arrays + virtualization DR products | Natively supported by the platform |
| Protection Granularity | Storage volume / LUN-level protection with unified data protection | VM-level protection for more granular, business-aligned DR |
| Compute-Side Dependency | The compute layer is responsible for VM state synchronization, failover orchestration, resource scheduling, and network recovery | Compute and storage are tightly integrated, with VM state synchronization, failover, resource scheduling, and network recovery automatically handled within a unified management platform |
| Failover Process | The overall switchover process requires cross-system operations and involves complex steps: 1. When a failure occurs at the source site, the storage volume must first be switched to the DR site. 2. The virtualization platform then manually starts the DR VMs or launches them through orchestration tools. 3. Network configuration and resource allocation must be adjusted separately to restore services. | The entire process is completed within a single platform, without cross-system operations, delivering shorter and more predictable RTO/RPO: 1. Once a failure occurs at the source site, failover is initiated in the management platform. 2. The DR cluster VMs are quickly started. Resource scheduling and network configuration are completed automatically at the same time. |
| Fault Domain Isolation | Depends on the overall architecture design and requires additional planning | Production and DR clusters are naturally isolated |
| Operations Model | Multi-platform operations across storage, virtualization, and DR tools | Unified operations through a single management platform |
Typical Use Cases
Traditional 3-Tier DR Architecture: Best suited for a storage-centric data center with mature infrastructure capabilities:
- Well-established storage systems: Existing deployments already include mid-range or high-end storage arrays with mature replication and DR capabilities.
- Preference for standardized and proven solutions: Organizations that favor storage-based DR mechanisms validated through long-term enterprise use.
- Sufficient resources and budget: Able to support the deployment and long-term operation of multiple systems and components.
Synchronous Replication: Best suited for environments seeking architectural simplicity and more flexible disaster recovery capabilities:
- Need to reduce architectural complexity: Integrates compute, storage, and DR capabilities into a single platform.
- Business-oriented data protection: Provides RPO=0 protection for critical workloads at the VM level.
- Unified O&M and monitoring: Centralizes data replication, failover, and recovery workflows within one platform, reducing operational complexity.
Technical Insight: Arcfra Operation Center (AOC) HA
With AOC HA capabilities, AECP 6.3 not only ensures the continuity of the data plane, but also enables automatic failover of the cross-site management plane, delivering more comprehensive disaster recovery protection.
HA Architecture

AOC consists of stateless services and stateful services, where stateful services mainly include databases and file data. To ensure continuous availability under failure scenarios, AOC supports high availability through cross-node deployment, with certain requirements on network stability and latency. The platform currently adopts a three-node HA architecture consisting of an active node, a passive node, and a witness node:
- Active Node: Hosts the management services and provides full control and management capabilities.
- Passive Node: Keeps data synchronized with the active node and can quickly take over services in the event of a failure.
- Witness Node: Responsible for health monitoring and failure detection, triggering automatic failover while preventing incorrect switchover under abnormal conditions.
At the data level, the database maintains consistency between the active and passive nodes through the synchronization mechanism, ensuring that in the event of a failover, the passive node can quickly take over services based on the latest data, thereby achieving continuous availability of the management plane.
Key Features
- Automatic failure detection and failover: Supports automatic health checks for the cluster and critical components. When an abnormal condition is detected, the system automatically triggers failover, enabling rapid service takeover and delivering a continuity guarantee with RPO = 0 and RTO ≤ 5 minutes.
- Cross-cluster and cross-data-center disaster recovery support: Supports DR deployment across clusters and data centers, with DR coverage extending to multiple same-city data centers, meeting the high availability and disaster recovery requirements of workloads at different levels.
- Health monitoring and alerting mechanism: Provides continuous monitoring of the HA cluster status. In scenarios such as resource anomalies, node failures, or unhealthy services, it can quickly detect issues and trigger alerts, helping O&M teams locate and resolve problems more efficiently.
Conclusion
To address the more stringent disaster recovery requirements of critical application scenarios, AECP 6.3 delivers a systematic upgrade to its DR architecture. By strengthening and unifying capabilities across the data plane, business plane, and management plane, it builds a full-stack disaster recovery system spanning data protection, business recovery, and platform control.
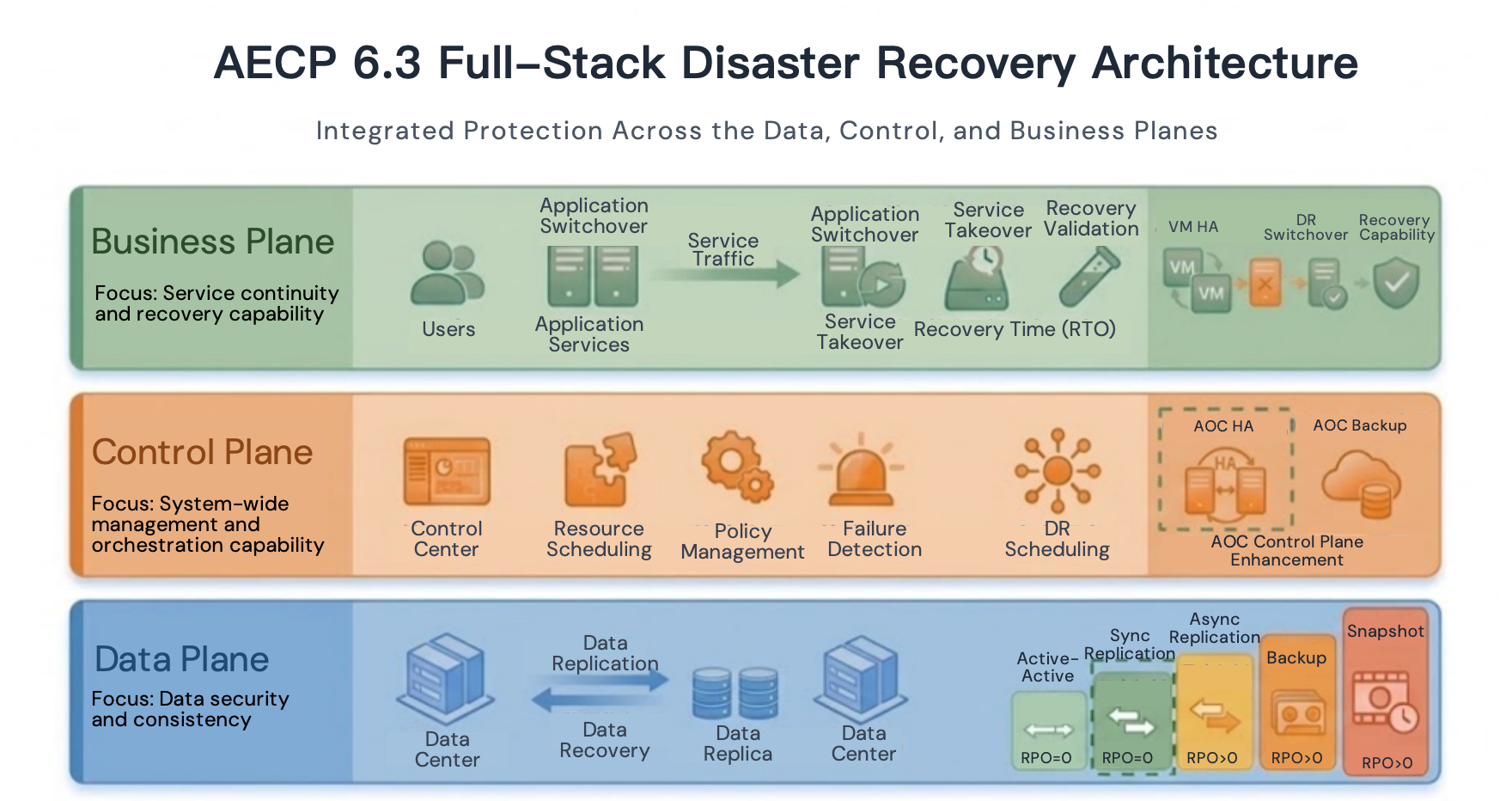
- Data Plane: From basic protection to data consistency assurance
Building on existing asynchronous replication and backup capabilities, AECP 6.3 introduces native synchronous replication to enable real-time data synchronization and data consistency assurance, delivering RPO=0 protection for critical workloads. - Business Plane: Assisted Recovery and Improved Operational Efficiency
With failure handling mechanisms and network remapping capabilities, workloads can be taken over and restored in an orderly manner according to predefined policies during disaster scenarios. This reduces the complexity of manual intervention and improves the predictability and efficiency of business recovery. - Control Plane: From single-point management to highly available scheduling
Building on AOC’s existing backup management capabilities, AECP 6.3 introduces a AOC HA architecture to ensure the control plane remains continuously available during disaster scenarios, enabling unified scheduling and uninterrupted operations throughout the recovery process.
Together, these three planes form a full-stack disaster recovery loop covering data protection, business recovery, and platform control. Disaster recovery is no longer limited to “recoverable data” — it evolves into a more complete capability where businesses can be recovered, processes can be controlled, and systems can remain continuously available.
Learn more about upgraded features and DR capabilities of AECP 6.3 from our latest blogs:
Arcfra AECP 6.3 Tech Insights: Stretched Cluster (Active-Active) vs. Synchronous Replication
Arcfra simplifies enterprise cloud infrastructure with a full-stack, software-defined platform built for the AI era. We deliver computing, storage, networking, security, Kubernetes, and more — all in one streamlined solution. Supporting VMs, containers, and AI workloads, Arcfra offers future-proof infrastructure trusted by enterprises across e-commerce, finance, and manufacturing. Arcfra is recognized by Gartner as a Representative Vendor in full-stack hyperconverged infrastructure. Learn more at www.arcfra.com.