
AI Infrastructure Decoded: AI Frameworks vs. Inference Engines
When enterprises move AI from experimental labs into private production environments, the technical vocabulary can quickly become a bottleneck. One of the most frequent points of confusion for IT teams is the distinction between the tools used to build a model and the tools used to run it.
In this installment of our “AI Infrastructure Decoded” series, we will break down the fundamental differences between AI Frameworks (the construction site) and Inference Engines (the engine room), helping your IT team build a bridge between model development and high-performance, sustainable operations.
What is the Distinction Between AI Frameworks and Inference Engines?
One-Sentence Answer: AI frameworks and inference engines are typically applied in the training and inference (running) stages of AI models, with the former largely focusing on model training while the latter on running and accelerating the well-trained models.
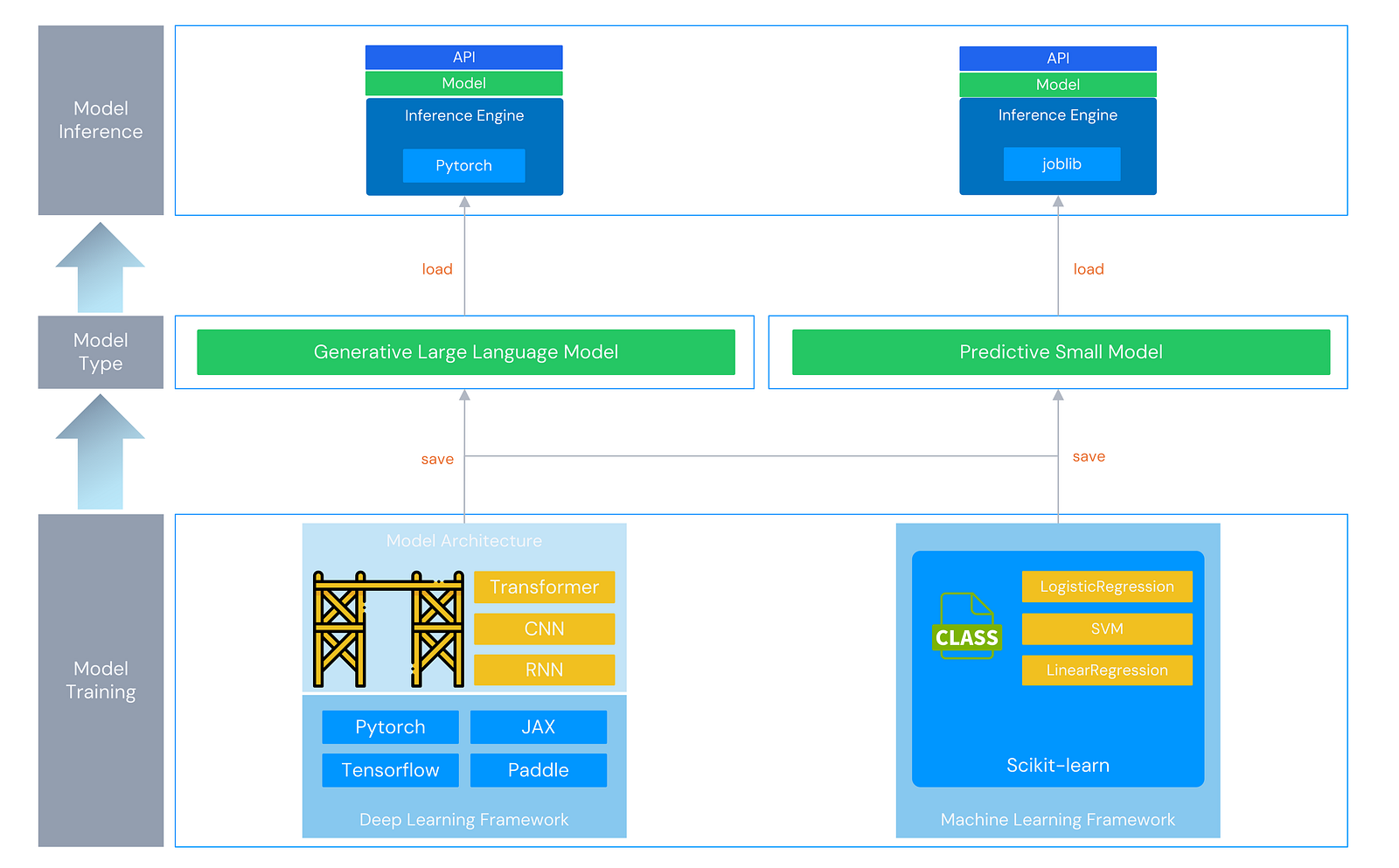
The core task of an AI model is to learn patterns from vast amounts of data to complete specific prediction or generation tasks; the former stage is “model training,” and the latter is “model running.” During model training, engineers typically prepare training data (training and test sets), and the AI framework calls the data to complete the model’s training. Once the model is trained, engineers distribute the model and run it via an inference engine. Users then invoke the model through an API to complete specific tasks.
For example:
- Game developers complete the development of a game (model) through various tools (AI frameworks).
- The game developer “burns” the developed game onto a cartridge or releases a digital version of the game on a platform (trained model).
- Players use a compatible console (inference engine) to play the game (use the model).
For different models, the AI frameworks and inference engines used vary.
Predictive Small Models
These models have fewer parameters and shallower layers. In solving classification problems such as spam detection, multivariate classification models such as Logistic Regression can be used to achieve prediction tasks. During training, the Scikit-learn (sklearn) machine learning framework in Python is typically used to quickly call the implemented logistic regression model, and training is completed through the fit method.
- Scikit-learn: A library specifically designed for machine learning; like os or math, it is one of the standard tools in the Python ecosystem.
- LogisticRegression: In sklearn, it can be called both a “model” and an “algorithm”; at the code level, it is represented as a class (LogisticRegression).
* eg: from sklearn.linear_model import LogisticRegression
Once the model is trained, it is typically saved in formats such as joblib or pkl and loaded and run via an inference engine. At this stage, the inference engine is primarily responsible for reading and loading the trained model file, providing a model prediction API interface, calling the model object’s predict method for prediction, and returning the prediction results to the user.
Generative Large Models
These models have more parameters and deeper layers, offering stronger expressive capabilities and higher accuracy. In solving problems such as text generation and summarization, architectures such as CNN, RNN, and Transformer can be used. During the training, generative models can be implemented based on different model architectures (CNN, RNN, and Transformer) with the help of deep learning frameworks such as PyTorch, TensorFlow, and JAX.
- PyTorch: A library specifically designed for deep learning; like os or math, it is one of the standard tools in the Python ecosystem.
- Transformer: Unlike the LogisticRegression mentioned above, Transformer is not a pre-implemented model but a framework for implementing a model, similar to scaffolding; a high-performance model can be implemented according to this framework through “classes” (import torch.nn as nn) implemented in PyTorch.
Once the model is trained, it is typically saved in formats such as safetensors or gguf and run using inference engines such as vLLM, SGLang, or llama.cpp. This type of inference engine is more complex: in addition to providing API interfaces and reading/loading models, it iteratively calls the model object’s forward() method to generate tokens step-by-step, manages KV-Cache, and returns the generation results to the user in real-time.
The entire process can be illustrated as below.
Learn more about Arcfra’s AI infrastructure solutions from our website and blog post:
AI Infrastructure Decoded: What is MaaS?
AI Infrastructure Decoded: What is ModelOps?
Powering AI Workloads with Arcfra: A Unified Full-Stack Platform for the AI Era
Arcfra simplifies enterprise cloud infrastructure with a full-stack, software-defined platform built for the AI era. We deliver computing, storage, networking, security, Kubernetes, and more — all in one streamlined solution. Supporting VMs, containers, and AI workloads, Arcfra offers future-proof infrastructure trusted by enterprises across e-commerce, finance, and manufacturing. Arcfra is recognized by Gartner as a Representative Vendor in full-stack hyperconverged infrastructure. Learn more at www.arcfra.com.